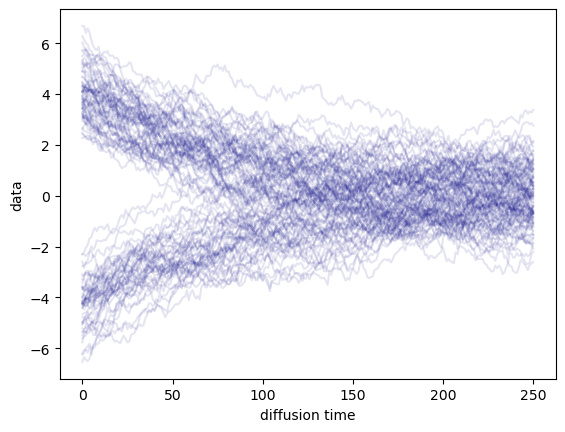
The solution to this problem lies in the way we store and load our data. Instead of trying to load all the data into memory at once, we can save it on disk and load only the samples we need when creating each batch. This approach, known as on-demand loading, allows us to work with datasets that are much larger than our available memory.
The major challenge that we face in this endeavor is speed. Loading data from disk is significantly slower than loading it from memory, so we need to ensure that this process is as efficient as possible to prevent it from becoming a bottleneck in our training pipeline.
In the following sections, we’ll delve deeper into these challenges and provide practical examples of how to overcome them using PyTorch Lightning. Here’s an UML diagram of how the solution will look like, I hope you will find it useful to navigate the post:
Pytorch Lightning
I am a big fan of Pytorch Lightning. It significantly reduces boilerplate code by providing a rich set of features, while maintaining a high degree of extensibility, modularity, and structure. One of the key components of PyTorch Lightning is the LightningModule, which encapsulates the core logic of the training process, including the forward pass, training step, validation step, and more. This is complemented by the LightningDataModule, which is responsible for organizing the data loading code. This clear separation of responsibilities between the data module and the training module makes the code easier to write, understand, and maintain.
As mentioned, LightningDataModule class is a blueprint for how to organize your data loading code, and it’s where we’ll implement our on-demand loading solution. The LightningDataModule class has several important methods that we’ll be using:
-
prepare_data: This method is called only once and is the place to download your data and perform any one-time preprocessing steps. It’s important to note that this method does not have access to the state of the LightningDataModule class, so it should not be used to set any instance variables.
-
setup: This method is called on every GPU in multi-GPU training and is used to perform any setup steps that require access to the dataset. For example, you might use this method to calculate the mean and standard deviation of your data for normalization purposes, splitting data into train and test set, etc.
-
train_dataloader and val_dataloader: These methods return the data loaders for the training and validation sets, respectively. They are called at the beginning of each epoch.
The lifecycle of the data module in a typical training run in PyTorch Lightning is as follows:
- prepare_data is called to download and preprocess the data.
- setup is called to perform any setup steps.
- The training loop begins, and train_dataloader is called to get the training data loader.
- The validation loop begins, and val_dataloader is called to get the validation data loader.
- Steps 3 and 4 are repeated for each epoch.
In the next section, we’ll see how we can use these methods to implement on-demand loading for large datasets.
Structure of the data module
Our solution to handling large datasets in PyTorch Lightning involves decoupling data preparation and data storage, and weaving them together in the data module. This allows us to easily change the storage method and the data pre-processing independently as the complexity of the application grows.
Specifically, Data preparation is offloaded to a DataPreparer object. This object retrieves samples from their original source, such as a remote database or the internet, and prepares each sample as necessary. Preparation could involve tasks such as normalizing numerical data, tokenizing text data, or resizing and normalizing images. The important thing is that all, or most, expensive pre-processing is done in this stage, rather than during training.
Once prepared, each sample is handled by a DataStorage object, which saves the sample on disk. In addition to samples, a DatasetInfo object is used to store basic information about the dataset. This information is necessary during the setup phase and could include the number of samples, the number of features, information necessary for stratified splitting for cross-validation, or a list of tokens for NLP applications.
In the setup method, we first load the dataset information from the storage. Then, we split the data into training and validation sets. The exact splitting method is not shown here but would depend on the specific requirements of your application. Finally, we create Dataset objects for the training and validation sets, which can be used to retrieve the data during training.
Here’s how this structure looks in code:
from typing import TypeVar, Generic, List, Tuple
TSample = TypeVar("TSample")
TInfo = TypeVar("TInfo")
class DataModule(Generic[TSample, TInfo], LightningDataModule):
"""
A LightningDataModule that decouples data preparation and storage.
"""
def __init__(
self,
storage: DataStorage[TSample, TInfo],
preparer: DataPreparer[TSample]
):
"""
Initializes the data module.
Args:
storage (DataStorage): The object responsible for storing the
data.
preparer (DataPreparer): The object responsible for preparing
the data.
"""
self._preparer = preparer
self._storage = storage
def prepare_data(self) -> None:
"""
Prepares the data by retrieving and preparing samples, then storing
them on disk.
"""
if self._storage.is_prepared():
return
self._storage.start_preparation()
for sample in self._preparer.prepare_data():
self._storage.save_sample(sample)
info = self._preparer.get_dataset_info()
self._storage.finish_preparation(info)
def setup(self, stage: str) -> None:
"""
Sets up the data module by loading the dataset information and
splitting the data into training and validation sets.
Args:
stage (str): The stage of the training process.
"""
super().setup(stage)
info = self._storage.load_dataset_info()
train_idx, val_idx = self.split(info)
self.train_dset = Dataset(train_idx, self._storage)
self.val_dset = Dataset(val_idx, self._storage)
def split(self, info: TInfo) -> Tuple[List[int], List[int]]:
# TODO implement splitting as appropriate
Dataset interface
As you can see from the setup method, the dataset makes use of the storage object to access a subset of the data samples depending on the given indices. A basic implementation could be as follows:
class Dataset(Generic[TSample]):
def __init__(self, indices: List[int], storage: DataStorage[TSample]):
self._indices = indices
self._storage = storage
def __len__(self) -> int:
return len(self._indices)
def __getitem__(self, idx: int) -> TSample:
return self._storage.load_sample(self._indices[idx])
For this implementation, it is important to distinguish between global and local indices. While global indices uniquely identify each available sample and are needed to load samples from storage, local indices are specific to the training and validation datasets, and are used by Pytorch to request loading of a specific sample in a dataset.
For example, if we have 100 samples available we could use the first 80 for training and the last 20 for validation. In this case, the sample with local index 0 in the validation dataset will have global index 80, local index 1 is global index 81, local index 19 is global index 99, etc.
The dataset above is given on creation the global indices of the subset it represents, and performs this translation from local to global index in the __getitem__ methor before invoking the storage.
This distinction will also be important later on.
Data preparation interface
The DataPreparer interface defines the blueprint for a class that prepares data for consumption by a deep learning model. It has two abstract methods that need to be implemented by any concrete subclass:
-
prepare_data: This method is responsible for preparing the data. It should return an iterator over the samples in the dataset. Each sample is of a generic type TSample, which could be as simple as a tuple of tensors, or more complicated objects. I personally like to use dataclasses for this, but anything goes.
-
get_dataset_info: This method should return a DatasetInfo object that contains information about the dataset. This could include things like the number of samples, the number of classes, the shape of the input data, etc.
The interface is as follows:
from abc import ABC, abstractmethod
from typing import Iterator, TypeVar
class DataPreparer(ABC):
"""
Abstract base class for a DataPreparer. A DataPreparer is responsible
for preparing data for a DataLoader.
"""
@abstractmethod
def prepare_data(self) -> Iterator[TSample]:
"""
This method is responsible for preparing the data. It should return
an iterator over the samples in the dataset.
"""
pass
@abstractmethod
def get_dataset_info(self) -> DatasetInfo:
"""
This method should return a DatasetInfo object that contains
information about the dataset.
"""
return None
By defining a DataPreparer interface, we can create different subclasses for different types of data (e.g., image data, text data, etc.), each implementing the prepare_data and get_dataset_info methods in a way that is appropriate for that type of data. We could also create more complex DataPreparers that extend or re-use simpler DataPreparers, for example multi-modal applications could have a specific preparer for each modality. This makes our data loading code more flexible and reusable.
Data storage interface
The DataStorage interface defines the blueprint for a class that handles the storage and retrieval of data samples and dataset information. It has several abstract methods that need to be implemented by any concrete subclass:
-
is_prepared: This method checks if the data has already been prepared. It should return True if the data has been prepared, and False otherwise, and is used to avoid unnecessary data processing.
-
start_preparation: This method starts the data preparation process. It might be used to set up necessary resources or state before data preparation begins.
-
save_sample: This method saves a prepared sample. The exact way in which the sample is saved will depend on the specific implementation and underlying storage.
-
finish_preparation: This method finishes the data preparation process. It might be used to clean up resources or state after data preparation is complete.
-
load_dataset_info: This method loads the dataset information. The returned information should be the same as the one saved with finish_preparation.
-
load_sample: This method loads a sample. The sample should be the same as the one saved with save_sample.
The first three methods are used when saving the dataset, while the latter two are used to obtain saved samples during training.
The interface is as follows:
from abc import ABC, abstractmethod
class DataStorage(Generic[TSample, TInfo], ABC):
"""
Abstract base class for a DataStorage. A DataStorage is responsible for
storing and retrieving data samples and dataset information.
"""
@abstractmethod
def is_prepared(self) -> bool:
"""
This method checks if the data has already been prepared. It should
return True if the data has been prepared, and False otherwise.
"""
pass
@abstractmethod
def start_preparation(self) -> None:
"""
This method starts the data preparation process. It might be used to
set up necessary resources or state before data preparation begins.
"""
pass
@abstractmethod
def save_sample(self, sample: TSample) -> None:
"""
This method saves a prepared sample. The exact way in which the
sample is saved will depend on the specific implementation and
underlying storage.
Args:
sample (TSample): The prepared sample to save.
"""
pass
@abstractmethod
def finish_preparation(self, info: TInfo) -> None:
"""
This method finishes the data preparation process. It might be used
to clean up resources or state after data preparation is complete.
Args:
info (TInfo): The dataset information to save.
"""
pass
@abstractmethod
def load_dataset_info(self) -> TInfo:
"""
This method loads the dataset information saved previously.
Returns:
TInfo: The loaded dataset information.
"""
pass
@abstractmethod
def load_sample(self, idx: int) -> TSample:
"""
This method loads a sample. The sample should be the same as the
one saved with `save_sample`.
Args:
idx (int): The index of the sample to load.
Returns:
TSample: The loaded sample.
"""
pass
By defining a DataStorage interface, we can create different subclasses for different types of storage (e.g., in-memory storage, disk-based storage, cloud-based storage, etc.), each implementing the above methods in a way that is appropriate for that type of storage. This makes our data storage code more flexible and reusable, as we are going to see in the next sections.
In-memory data storage
Before going all-in on disk storage, let’s see a much simpler example.
In-memory data storage is the simplest and most efficient method for handling data when all samples fit into memory. In this case, we can save all samples into a single file and load the file only once when the first sample is requested. Then, we keep the file in memory so that loading all subsequent samples is very fast.
Here’s how this concept is implemented in the InMemoryDataStorage class:
import os
class InMemoryDataStorage(DataStorage[TSample, TInfo]):
def __init__(self, datafile: str):
self.datafile = datafile
self._samples: Optional[List[TSample]] = None
self._info = None
def is_prepared(self) -> bool:
return os.path.exists(self.datafile)
def start_preparation(self) -> None:
self._samples = []
def save_sample(self, sample: TSample) -> None:
if self._samples is None:
raise RuntimeError("please call start_preparation before save_sample")
self._samples.append(sample)
def finish_preparation(self, info: TInfo) -> None:
torch.save((self._samples, info), self.datafile)
def load_dataset_info(self) -> TInfo:
if self._info is None:
self._samples, self._info = torch.load(self.datafile)
return self._info
def load_sample(self, idx: int) -> TSample:
if self._samples is None:
self._samples, self._info = torch.load(self.datafile)
return self._samples[idx]
During data preparation, we append each sample to a list, and, once all samples have been prepared, they are saved to the specified file along with the dataset information.
When we need to load the dataset information or a specific sample, we first check if the data has been loaded into memory. If not, we load the data from the file. This ensures that the file is only loaded once, and all subsequent accesses performed from the object saved in memory.
On-disk data storage
The InMemoryDataStorage is an excellent solution when all data can be accommodated in memory. However, in instances where this is not feasible, we must resort to on-demand loading of samples from disk. Most importantly, the way in which sampels are stored significantly influences data retrieval speed.
Typically, file access incurs a roughly constant overhead, dependent on the storage technology, in addition to a variable delay based on the file size. Disks generally perform optimally when tasked with reading and writing large data chunks sequentially, as opposed to numerous small, random reads or writes.
In the context of Solid State Drives (SSDs), for instance, the hardware is usually capable of reading a minimum size of about 4 KB. Consequently, storing files smaller than this minimum size offers no speed advantage, as the SSD will still read the minimum size, regardless of the actual file size. Furthermore, SSDs comprise several flash memory chips that can be accessed simultaneously when working with sufficiently large files. However, smaller files would only access a single chip, thereby not benefiting from the hardware parallelism.
In the case of Hard Disk Drives (HDDs), file access begins with disk seeks, which involve moving the read/write head to the correct disk location. This mechanical operation takes a significant amount of time. However, once the initial seek is completed, sequential access is quite speedy, as the read/write head remains stationary while the disk platter spins beneath it.
The implication of these factors is that disks cannot achieve peak performance when frequently accessing small files. Therefore, saving each sample in a separate file is not the most efficient method.
For this reason, we instead create blocks of samples that are saved together in a single file. For instance, we could save 100, 1000, or even 10000 samples in the same file. The optimal number of samples per file depends on the final file size on disk, the speed of reading it, etc. Nonetheless, a good starting point could be 1000 samples per file.
Here’s how this concept is implemented in the OnDiskBlockDataStorage class:
import pickle
class OnDiskBlockDataStorage(DataStorage[TSample, TInfo]):
def __init__(self, base_folder: str, block_size: int = 5000):
self.base_folder = base_folder
self.block_size = block_size
self.datafile = os.path.join(base_folder, "dataset_info.pkl")
self._info = None
self._sample_count = self.block_count = 0
self._current_saving_block: Optional[List[TSample]] = None
self._loaded_block: Optional[List[TSample]] = None
self._loaded_block_idx: Optional[int] = None
def is_prepared(self) -> bool:
return os.path.exists(self.datafile)
def start_preparation(self) -> None:
self._current_saving_block = []
def save_sample(self, sample: TSample) -> None:
if self._current_saving_block is None:
raise RuntimeError(
"please call start_preparation before saving samples"
)
self._current_saving_block.append(sample)
self._sample_count += 1
if len(self._current_saving_block) >= self.block_size:
self._save_current_block_and_start_new()
def _save_current_block_and_start_new(self) -> None:
dest_path = self._block_path(self.block_count)
dest_folder, _ = os.path.split(dest_path)
os.makedirs(dest_folder, exist_ok=True)
torch.save(self._current_saving_block, dest_path)
self._current_saving_block = []
self.block_count += 1
def _block_path(self, block_id: int) -> str:
return os.path.join(self.base_folder, "blocks", f"{block_id}.pt")
def finish_preparation(self, info: TInfo) -> None:
if self._current_saving_block:
self._save_current_block_and_start_new()
with open(self.datafile, "wb") as f:
# use protocol 4 to save large obejcts
pickle.dump(
(info, self.block_count, self.block_size),
f, protocol=4
)
def load_dataset_info(self) -> TInfo:
if self._info is None:
with open(self.datafile, "rb") as f:
data = pickle.load(f)
self._info, self.block_count, self.block_size = data
return self._info
def load_sample(self, idx: int) -> TSample:
block_id = idx // self.block_size
offset = idx % self.block_size
if self._loaded_block_idx != block_id:
block_path = self._block_path(block_id)
self._loaded_block = torch.load(block_path)
self._loaded_block_idx = block_id
return self._loaded_block[offset]
During data preparation, we create an empty list to store the block of samples being constructed. When the number of samples in the list reaches the desired block size, we save all of these samples to a single file. Once all samples have been prepared, we also save the provided dataset information, block count, and block size to a separate file. This file also serves as sentinel to determine if the dataset preparation was already performed.
When we need to load a specific sample, we check if the corresponding block has been loaded into memory. If not, we first load the entire block from the file, then we return the sample that was requested.
Random sampling with block storage
Saving data in blocks does however pose an additional challenge when accessing samples in a random order.
Random sampling is crucial in training deep learning models because it helps to prevent overfitting and ensures that the model generalizes well. It does this by breaking potential correlations in the data and ensuring that each training batch is a good representation of the overall dataset. This randomness ensures that the model doesn’t learn the order of the training data, which could lead to poor performance on unseen data. In technical terms, random sampling is an unbiased estimator of the loss gradient with respect to the dataset, which is the reason why mini-batch training is possible.
However, when data is saved in blocks as we did above, entirely random access is rather inefficient as it requires loading an entire block from disk each time a single sample is needed, since samples in a random order are likely to belong to different blocks.
The solution to this problem is to build a custom sampler that selects blocks in a random order, then yields all samples in that block also in a random order. This approach maintains the benefits of random sampling while also taking advantage of the efficiency of block data loading.
While this solution is not perfectly random, as samples within the same block are more likely to appear in the same batch, it is typically good enough for practical purposes as long as the blocks are large enough, and the samples were divided into blocks randomly during preparation. In this case the batches will still contain a good variety of samples; for example, there are 2.3e60 different batches of 32 elements that can be constructed from a single blocks of size 1000.
This approach can be implemented using a custom sampler with PyTorch’s DataLoader. DataLoaders in PyTorch are used to load data in complex ways, such as multi-threaded data loading and custom sampling strategies. They use samplers to specify the sequence of indices/keys used in data loading.
There are several common types of samplers used in PyTorch:
- SequentialSampler: This sampler loads data in a sequential order. It’s useful when you want to go through the dataset in the same order every time, most commonly used in the validation dataset.
- RandomSampler: This sampler loads data in a random order. It’s useful when you want to shuffle your data, as should be done for teh training dataset.
- BatchSampler: This sampler loads data in mini-batches. It’s useful when you want to load data in chunks rather than one sample at a time. It is typically composed with other samplers such as the ones described above.
In our case, we would write a custom sampler that selects blocks in a random order, and then selects samples within each block in a random order. We then combine this custom sampler with the BatchSampler and use it with the standard Pytorch DataLoader.
This is where the distinction between global and local sample indices described above with the dataset becomes relevant. The sampler also needs to return local indices, but do so in such a way that local indices in the same batch correspond to global indices that were stored in the same block.
class BlockSampler:
"""
A custom sampler class that groups samples into blocks and yields
samples from the same block before moving on to the next block.
The blocks and samples within blocks can be accessed in a random or
sequential order, based on the `shuffle` parameter.
"""
def __init__(
self,
indices: List[int],
block_size: int,
shuffle: bool
) -> None:
"""
Initializes the BlockSampler.
Args:
indices (List[int]): A list of global sample indices contained
by the dataset.
block_size (int): The number of samples in each block.
shuffle (bool): If True, blocks and samples within blocks are
accessed in a random order. If False, they are accessed
sequentially.
"""
self._block_size = block_size
self._shuffle = shuffle
self._indices = indices
self._blocks: Dict[int, List[int]] = {}
# use global indices to identify the blocks spanned by this
# dataset, and store in each block the corresponding local index
# of the sample
for local_idx, global_idx in enumerate(indices):
b = global_idx // block_size
if b not in self._blocks:
self._blocks[b] = []
self._blocks[b].append(local_idx)
def __len__(self) -> int:
"""
Returns the total number of samples.
"""
return len(self._indices)
def __iter__(self) -> Iterator[int]:
"""
Yields sample indices such that each block is only visited once.
"""
block_sequence = self._sequence(self._blocks.keys())
for block in block_sequence:
sample_sequence = self._sequence(self._blocks[block])
for sample in sample_sequence:
yield sample
def _sequence(self, indices: Sequence[int]) -> Iterator[int]:
sorted_indices = sorted(indices)
if self._shuffle:
yield from np.random.choice(
list(sorted_indices),
size=len(sorted_indices),
replace=False
)
else:
yield from sorted_indices
The BlockSampler class is a custom sampler that groups samples into blocks and yields samples from the same block before moving on to the next block. This is achieved by dividing the global indices by the block size to get the block number for each sample, and then storing the local indices of the samples in the corresponding block.
Finally, we need to use this sampler, if appropriate, when creating the data loaders for the training and validation dataset:
class DataModule(LightningDataModule):
# previous code ...
def train_dataloader(self) -> DataLoader[DataSample]:
sam = self._get_sampler(self.train_dset, shuffle=True)
return DataLoader(
self.train_dset,
num_workers=self.num_workers,
collate_fn=self.train_dset.collate,
batch_size=None,
sampler=sam,
)
def val_dataloader(self) -> DataLoader[DataSample]:
sam = self._get_sampler(self.val_dset, shuffle=False)
return DataLoader(
self.val_dset,
num_workers=self.num_workers,
collate_fn=self.val_dset.collate,
batch_size=None,
sampler=sam,
)
def _get_sampler(self, dataset: Dataset, shuffle: bool) -> Any:
"""
Returns a BatchSampler that uses a BlockSampler as its inner
sampler if the storage saved data in blocks, otherwise a random
or sequential sampler.
Args:
dataset (Dataset): The dataset for which to get the sampler.
shuffle (bool): If True, samples are accessed a random order, otherwise they are accessed sequentially.
Returns:
BatchSampler: A BatchSampler.
"""
if isinstance(self.storage, OnDiskBlockDataStorage):
inner_sampler = BlockSampler(
dataset.indices, self.storage.block_size, shuffle=shuffle
)
elif shuffle:
inner_sampler = RandomSampler(dataset)
else:
inner_sampler = SequentialSampler(dataset)
return BatchSampler(inner_sampler, self.batch_size, drop_last=False)
Conclusion
In this blog post we saw how to efficiently load data from disk in PyTorch Lightning when it does not all fit in memory. The solution involves saving groups of samples into a single file, and using a custom sampler to enable almost-random access to these samples while minimizing disk reads, by iterating over the blocks one at a time.
]]>